TLDR
In this post, I will cover concepts in reinforcement learning (RL), specifically Q-Learning, applied to the context of maximizing returns in a simulated stock market environment.
Enjoy!🙂
Q-Learning
As briefly described above, Q-Learning is an RL technique that learns the optimal strategy (called a policy in RL) from three distinct elements: the action space, the state space, and a reward function. Interestingly, the “Q” in Q-Learning comes from the act of focusing on the quality of each action, and choosing the best action.
In its simplest form, the algorithm has a function,
Actions
The action space, denoted
States
The state space, denoted
These input features must go through some function,
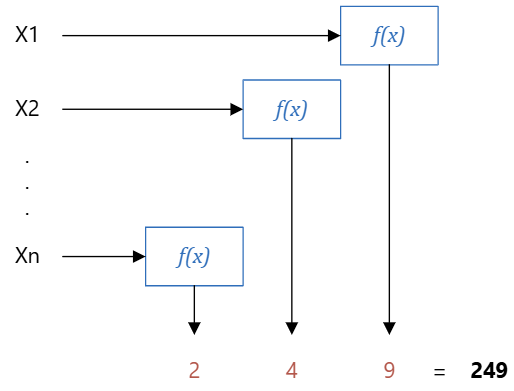
The function
Reward Function
Perhaps the most important pillar of a Q-Learner is the reward function,
This decision will impact the time it will take for the learner to learn. Lots of questions need to be answered, mainly how do we reward our learner for making good trades, or penalize the learner for making subpar trades? What factors should be considered when making this decision? Do we base it on daily returns, or cumulative return for a prospective trade?
Q-Learners will converge to the optimal policy much faster when immediate reward is used.2 In the context of pet training, immediately rewarding the animal after each success will help the animal to associate each action with positive reinforcement.
Conclusion
In this post, we’ve gone through an introduction to Q-Learning—the three pillars, what they mean, and how we can apply this in a simulated market. Simply put, a Q-Learner uses the current state and tries out different actions to see what happens.
Based on the reward of an action, it learns which actions are the best to take in similar situations in the future. We also covered discretization, or the process of representing continuous data as discrete integers, and the importance of this in determining states.